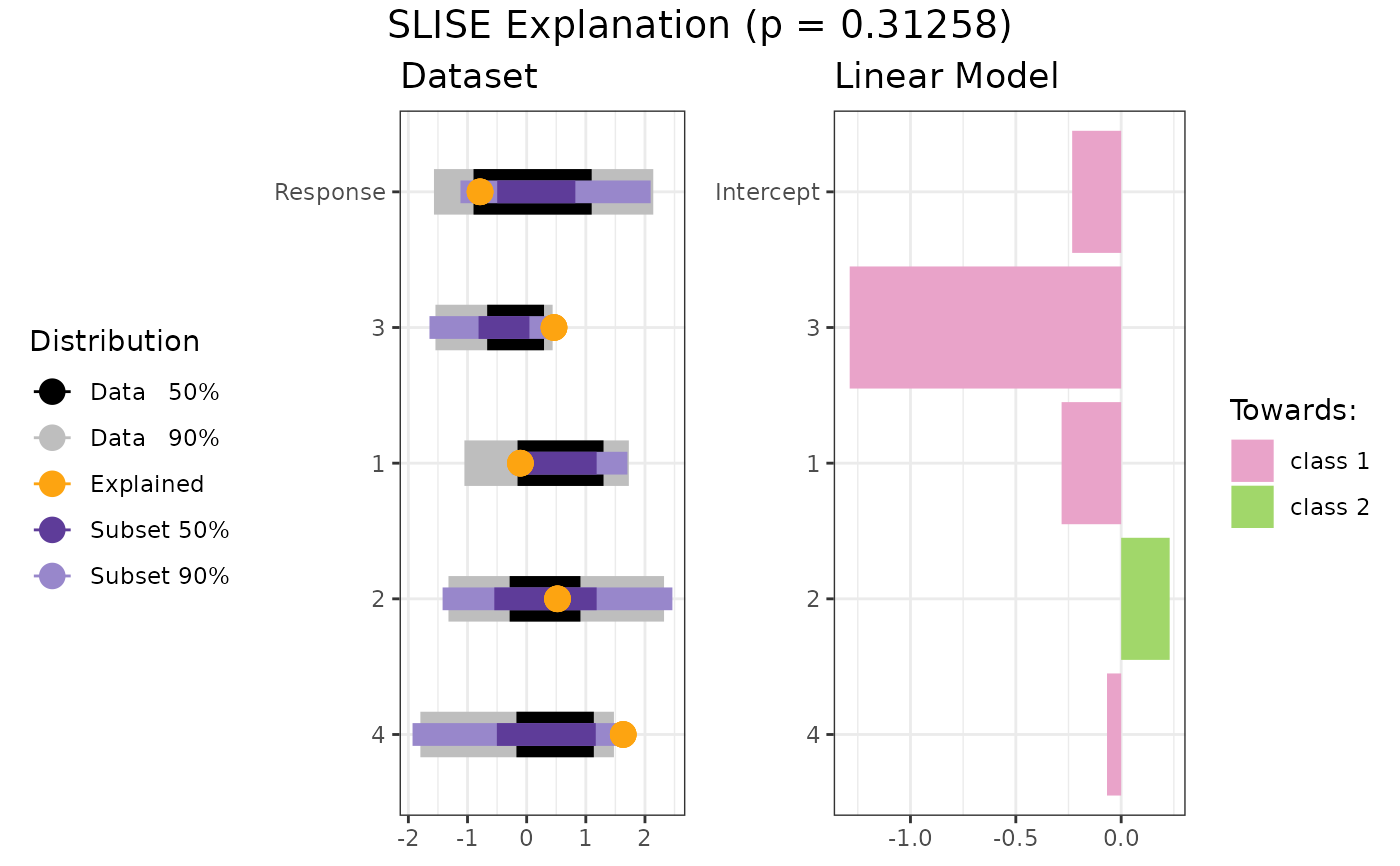
It is highly recommended that you normalise the data, either before using SLISE or by setting normalise = TRUE.
Usage
slise.explain(
X,
Y,
epsilon,
x,
y = NULL,
lambda1 = 0,
lambda2 = 0,
weight = NULL,
normalise = FALSE,
logit = FALSE,
initialisation = slise_initialisation_candidates,
...
)Arguments
- X
Matrix of independent variables
- Y
Vector of the dependent variable
- epsilon
Error tolerance
- x
The sample to be explained (or index if y is null)
- y
The prediction to be explained (default: NULL)
- lambda1
L1 regularisation coefficient (default: 0)
- lambda2
L2 regularisation coefficient (default: 0)
- weight
Optional weight vector (default: NULL)
- normalise
Preprocess X and Y by scaling, note that epsilon is not scaled (default: FALSE)
- logit
Logit transform Y from probabilities to real values (default: FALSE)
- initialisation
function that gives the initial alpha and beta, or a list containing the initial alpha and beta (default: slise_initialisation_candidates)
- ...
Arguments passed on to
graduated_optimisation,slise_initialisation_candidatesbeta_maxStopping sigmoid steepness (default: 20 / epsilon^2)
max_approxApproximation ratio when selecting the next beta (default: 1.15)
max_iterationsMaximum number of OWL-QN iterations (default: 300)
debugShould debug statement be printed each iteration (default: FALSE)
num_initthe number of initial subsets to generate (default: 500)
beta_max_initthe maximum sigmoid steepness in the initialisation
pca_tresholdthe maximum number of columns without using PCA (default: 10)